![]()
If you use IDA Pro with the Zynamics BinDiff plug-in you might find this useful.
My little fixer plug-in here (or followed patch instructions) will improve the speed of the “Import Symbols and Comments..” aka “port” feature by over 3000% (yes you read that correctly, three thousand percent!)
The BinDiff plug-in is/was landmark technology. Anyone using IDA for any length of time probably wished for some way to relate the contents of one IDB to another, and to carry on (or just relating) your work by having comments, names and other symbols “ported” from one version IDB to the next.
Google for it and you will find white papers and presentations by it’s ingenious creator Halvar Flake.
About “malvare”:
A white paper on using BinDiff.
Great in concept, but the actual implementation not with out several problems.
The earlier versions were very rough and would crash most of the time, plus would literally take half a day to complete (if it would at all) on anything but very small IDBs. They appeared to use some rather archaic, and, or, over OOP-ification design paradigms (vrs say more functional data-driven ones).
Plus ringing up at about $1200 USD (twice the cost of the base IDA package it’s self) IMHO overpriced (but granted, I don’t know the economics of it).
Much has improved in the latest version and now a much more reasonable price.
It still sporadically crashes fairly often and still no visual UI feedback of progress (leaving you wondering if it’s still running or if it has crashed). It’s much faster in the diffing stage now, but the port feature was still very slow; in particular I noticed the same odd issue, excessive disk activity. Really, my drive sounded like the business end of an A-10 Gatling cannon as this thing ran.
As I didn’t want my hard drive to spontaneously combust, also to possibly speed things up, and to generally see if I could use it as I tool, I decided to take a look.
I had an idea, why not to make it use a RAMDisk!?! In particular the new free AMD RAMDisk (using Dataram Corp technology).
I made my own little plug-in (they are DLLs after all) to hook kernel32->GetTempPathA() and redirect to this RAMDisk.
And viola, that did it!
My port times went down from over ~55 to just ~1.6 minutes, that’s 34.5 times faster!
Incidentally the last time I really played with RAMDisks was probably in the late 90’s.
This AMD/Dataram one has a lot of nice features like optional automatic disk image save, and, or, restoring, etc.
If I had the system memory to spare (say 32GB or more) I might try mounting my whole tools folder, and, or, large games from it too.
Check out the stats on it, this RAMDisk has typically twice the performance of the typical SSD!
Then a week later it dawned on me where I’ve seen some devs put some sort of file flush (probably inadvertently) in their code path (like an fflush() API call).
I know from experience the side effects. What these files flushes do is essentially shunt the whole OS file buffering mechanism. It forces what ever is in the file write buffer(s) to be immediately written to disk.
They have their legitimate uses of course. I have for exampled used such flushes in low level exception handlers, etc., where you need to make sure your log file data gets written to disk before the process exits.
But if you put them in your inner loops, where you write to file(s), you’ll just kill your performance.
A quick look inside “zynamics_bindiff_4_0.plw” and sure enough two API imports of interest can be seen: FlushFileBuffers(), and fflush().
Yes, indeed FlushFileBuffers() was the culprit. It was called ~142 times during the Diff stage that probably made little difference in performance, but where it was a problem was the 126,394 times called during the port process. I didn’t look much further, but it appears some of these flushes are called, like it or not, on the dtor of some std::fstream stuff.
A kernel32->FlushFileBuffers() hook filtering out the call to do nothing in my DLL, the port feature was back down to about 1.65 seconds.
That’s a 3437% improvement in speed! Plus now a RAMDisk was not needed.
As I write this I’ll report the issue to Zynamics to be fixed for the next BinDiff version, but for now you can do one of two things:
Use the attached “ZyFixer” plug-in, or just binary patch your “zynamics_bindiff_4_0.plw” file directly.
To use the plug-in just drop it in your “plugins” folder. Then the next time you start up IDA it will hook FlushFileBuffers() to do nothing (skipping the actual flush action) when called from zynamics modules. Source is included.
Patching the plug-in should be easy enough with a file hex editor like WinHex, HxD, etc.
At around file offset 0x93F20 (RVA 0x10094B20) you should find this function:
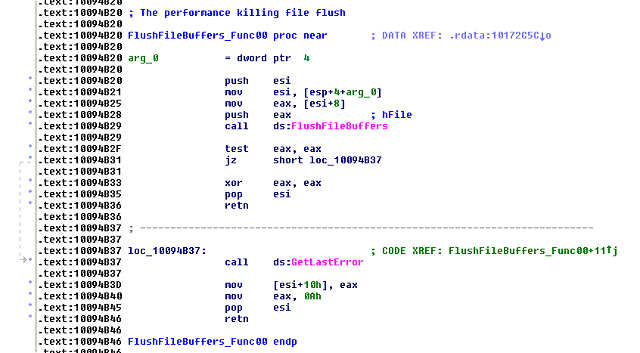 .
.
Just patch it with a: “sub eax,eax”, “retn” (that’s bytes “2B,C0,C3”) and save.
Enjoy waiting just 1/34th the time for the port feature to finish..
2 thoughts on “Speed up the Zynamics BinDiff “port” feature by 3000%”
Leave a Reply
You must be logged in to post a comment.
Hey, I’m the author of the BinDiff engine and plugin – thank you for the bug report and fix. It never ceases to amaze me how engaged and knowledgeable our customers are 😉
I’ll look into the issue. My first hunch: Are you using loaded results for comment porting? (As opposed to performing the diff and then porting directly). We have an unfortunate hack in the plugin based on the fact that we have to share an address space with the IDA 32 bit application and thus have very little memory available to do our work. In order to allow processing very large diffs we support a mode where you can use a 64 bit standalone command line executable to perform the diff and then load the results into IDA. Results are then loaded lazily on demand. This requires a lot of minor disk accesses. However, using this for comment porting means we’ll be loading the whole export serially piece by piece, writing temporary files per flow graph as we go. That’s likely the cause for the slow down you encountered.
I’d be interested in any idbs that cause the differ to crash. The core engine should be rather robust by now – we’ve processed more than 100 Billion diffs internally without a hitch. There are some pathological cases where the algorithm will exhibit very bad runtime behavior. This is to be expected for a complex set of heuristics trying to solve an NP-complete problem (related to the: http://en.wikipedia.org/wiki/Subgraph_isomorphism_problem).
Thanks again for the report!
Your welcome and thanks for visiting.
Yea, going the “performing the diff and then porting directly” route.
Knowing the DarunGrim source (which also uses the block graph thing) it’s a very memory intensive thing; as opposed to raw algorithmic FLOPS as I originally thought.
Like back in the days of 64KB (if even 16KB) address spaces, I can see it’s hitting the 2GB wall with a tool like this 😉
IMHO things should get easier as the PC world seems to be migrating towards 64bit more.
Although I wonder if there is room to reduce like using bits instead of bytes (if at all possible), using more hashing, or using fast run time compression, etc.
Easier said then done though.