Today, I’ll show off this IDA plug-in I made over a few months last summer.
I ended up with basically an enhanced replacement for IDA Pro’s Strings window that understands many character set encodings (of the multi-byte foreign language kind, other then our ubiquitous friend ASCII), extracts ambiguous UTF-16 strings (real ones, using code pages beyond “ASCII-16″/Latin 1), with some statistical understanding of languages, and wrapped up with some automated web translation to translate the found “foreign” strings into English.
StringMiner™ screenshot:
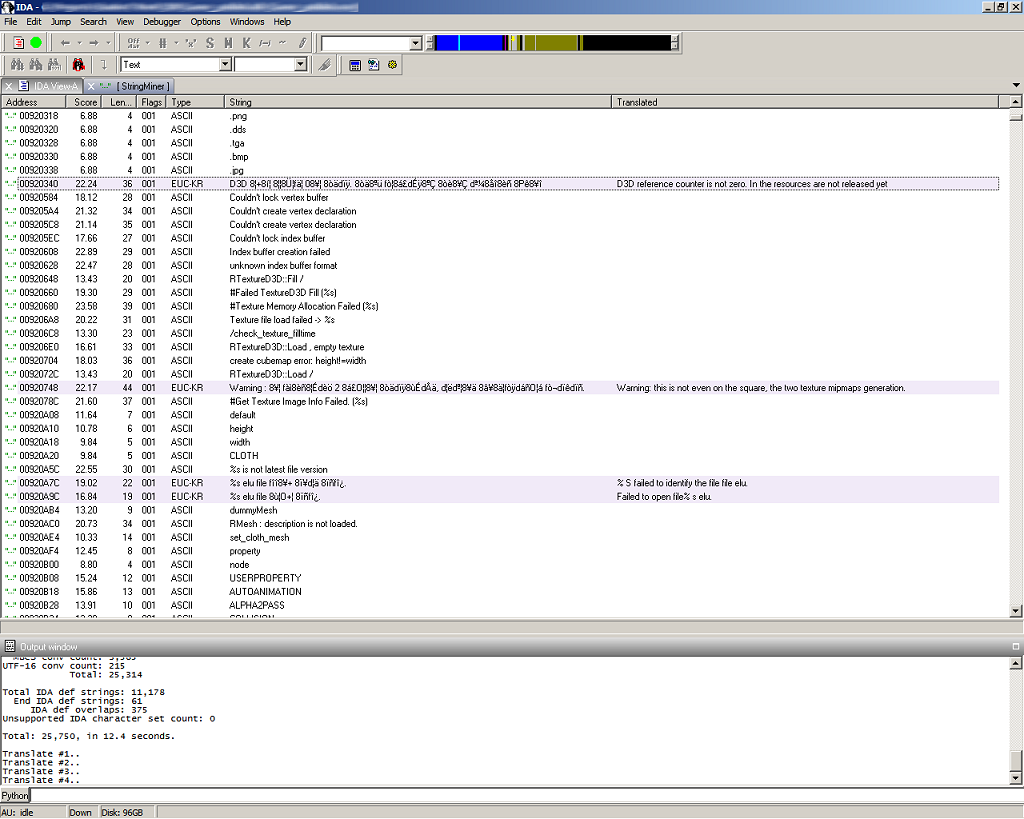
At first I set out just to solve an annoying problem with IDA where it would occasionally miss valuable text strings.
I’d be browsing around, typically in the .rdata and .data sections, of an x86 target executable and notice that some strings were not in the “Strings Window” as they should be.
It seemed the problem was particularly prevalent with certain executables, like ones that just have a lot of strings in general, or in such a state that code references to the strings were missing et al.
As you may know with reverse engineering it’s often, at least feels, like your putting together a big puzzle.
Some times parts of it come together quick conceptually, while other times you might spend hours (maybe days) mulling over and piecing things together until it all clicks in (depending on the size and scope).
Text strings can be particularly useful as they might instantly put some contextual meaning to a particular area of code (or data); they can be important.
Now, not saying IDA is bad or particularly faulty, as it does amazingly well for the majority of what it is supposed to do. Just that some times it makes the wrong guess.
You might be familiar with Mark Russinovich’s useful Strings utility, or Luigi Auriemma’s more advanced Executable’s strings lister and replacer for extracting strings from binaries.
Algorithmically they work the same way. They extract strings by walking the input data looking for patterns of pure ASCII range. Valid ASCII characters (in range byte/char range from about 0 to 127), using API calls like isprint() to test for valid characters. And the same for UTF-16 for a repeated ASCII byte, zero byte pattern. This is only a limited (albeit fairly common) “Latin 1” subset, what Ralph Brown calls “ASCII-16”, of the whole UTF-16 code page range that can cover a wide range of language encodings.
I started on a similar path with my plug-in to run the same type of simple algorithm to find my missing strings.
Also another thing I had been trying to solve for a while is how to view foreign language strings.
“Foreign” being a relative term of course.
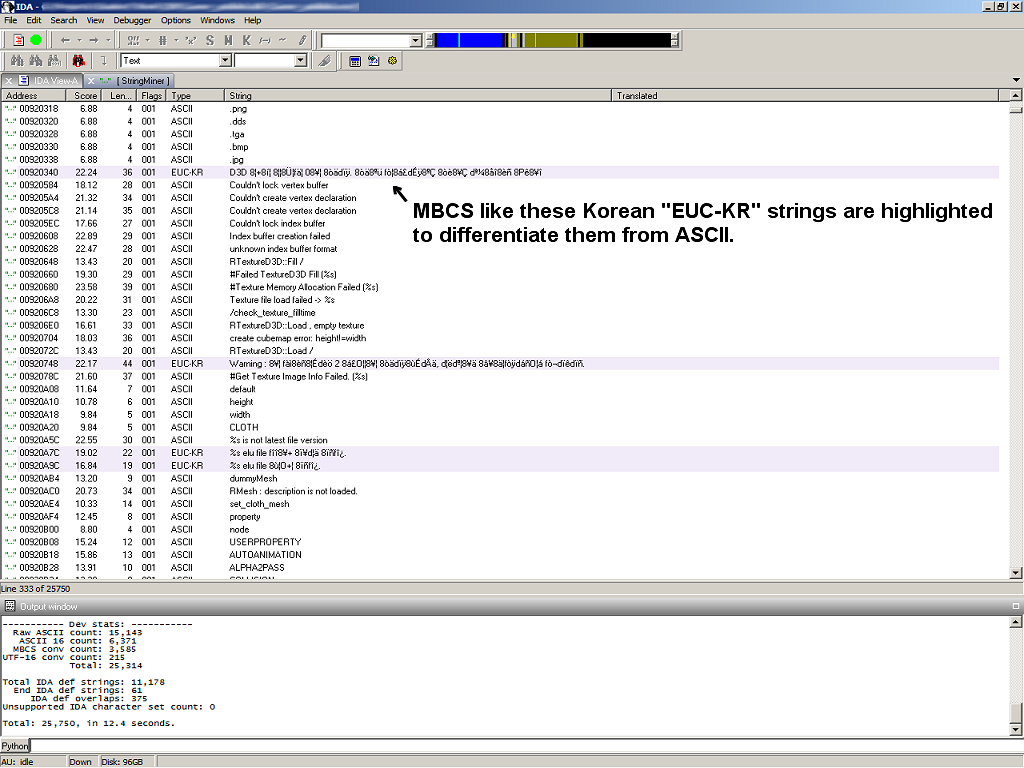
In some targets I’d find typically Chinese or Korean encoded strings. I wanted to identify and find some way to read them.
I sort of handled it before with lot of manual steps using a plug-in I made where it could dump selected strings to a text file, then I’d text file up in a browser where I would set the appropriate text encoding option to view it natively, then finally copy and paste the properly encoded text one line at the time into yet another browser window to be web translated.
While researching the topic on the web I ran into Ralph Brown’s amazing Language-Aware String Extractor project!
Enhanced version of the standard Unix strings(1) program which uses language models for automatic language identification and character-set identification, supporting over 1000 languages, dozens of character encodings, and 3500+ language/encoding pairs.
Incidentally if you’re from the DOS days, you might recognize Ralph Brown as the author of the “Bible” of interrupt lists that we all used to interface with the PC hardware.
Okay, this was the ticket. I’ll take Ralph’s code and convert it into a plug-in.
But it wasn’t so simple. It had a huge Linux library (a lot of which wasn’t even being used) deeply entwined that I had to rip out.
And Ralph I love you (figuratively speaking), but it’s not the easiest code base to deal with (but then who’s is after all?).
Then digging into it deeper and understanding the science behind it, I realized how ambiguous the whole solution is. It is after all statistically based, not finite.
That’s just how the data is. It’s literally “needles in a hay stack”.
A good description from the ICU User Guide:
Character set detection is the process of determining the character set, or encoding, of character data in an unknown format. This is, at best, an imprecise operation using statistics and heuristics.
Some of the supported character encodings are indeed very ambiguous.
Tends to be more bit populated entropy wise, but one of the worst is UTF-16 (in code ranges beyond ASCII, other then English). Runs of UTF-16 bytes might look like any other runs of bytes.
I had to give UTF-16 special attention, processing it in a 2nd pass (after ASCII and the multi-byte sets had their chance), and relied on the fact that on the PC these strings will be evenly aligned, etc.
Note yea this is all very PC-centric, but it could be expanded to any number of platforms where one needs to extract such strings.
And while “1000 languages, dozens of character encodings” (and growing) sounds great, I had to really narrow down the data set to the ones I’d most likely encounter, and allow the selection of only the ones of interest to get things to work properly. Else the output would be full of false positives, and one encoding would trample over another et al.
I’d say the tool is about 80% done, could certainly use more honing and tweaking.
Along the way I evaluated and added two other related engines, the Mozilla universal charset detector, and the ICU Character Set Detection library. I tried the Windows native Microsoft MLang character detector, but it was just horrible; Returned incorrect results the majority of the time, at least for the necessarily small to medium string length inputs anyhow.
I wanted to have it where it would do an optional pass over the data (typically just the “.rdata” and “.data” segments) and automatically figure out what character sets are being used, but it’s not a trivial thing to do as there is a lot of variants to it.
What I did instead (at least for now) was add a character set “guess” feature, so that I could probe around to determine what sets are being used.
Needs more work with practical things like a UI fancy enough to allow the selection of character sets of interest, etc., so don’t know when if at all if I release it all.
Now on with some more demonstration…
The encoding detection feature:
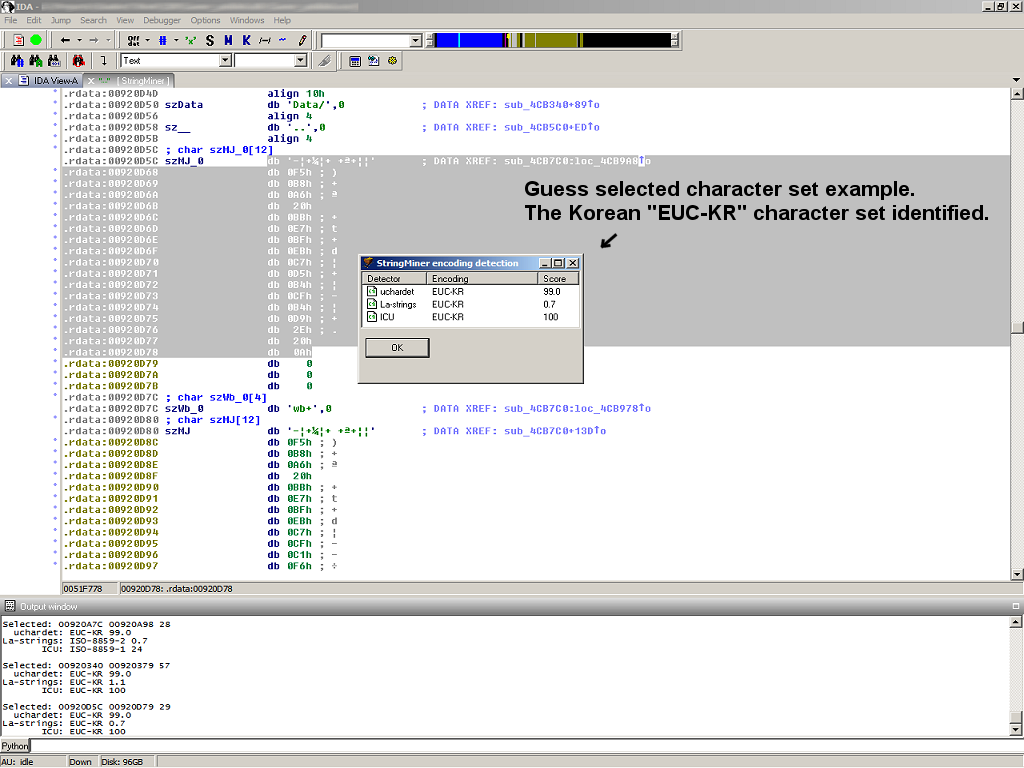
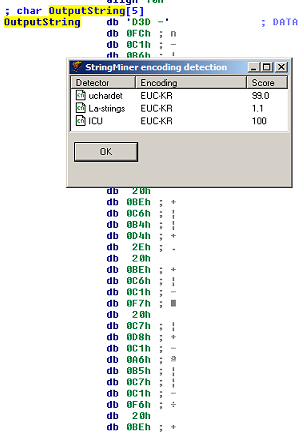
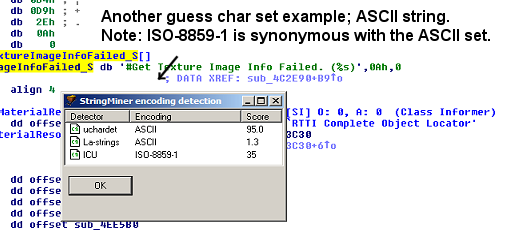
StringMiner™ list/chooser window:
Gentle color highlighting:

MBCS = multi-byte character set.
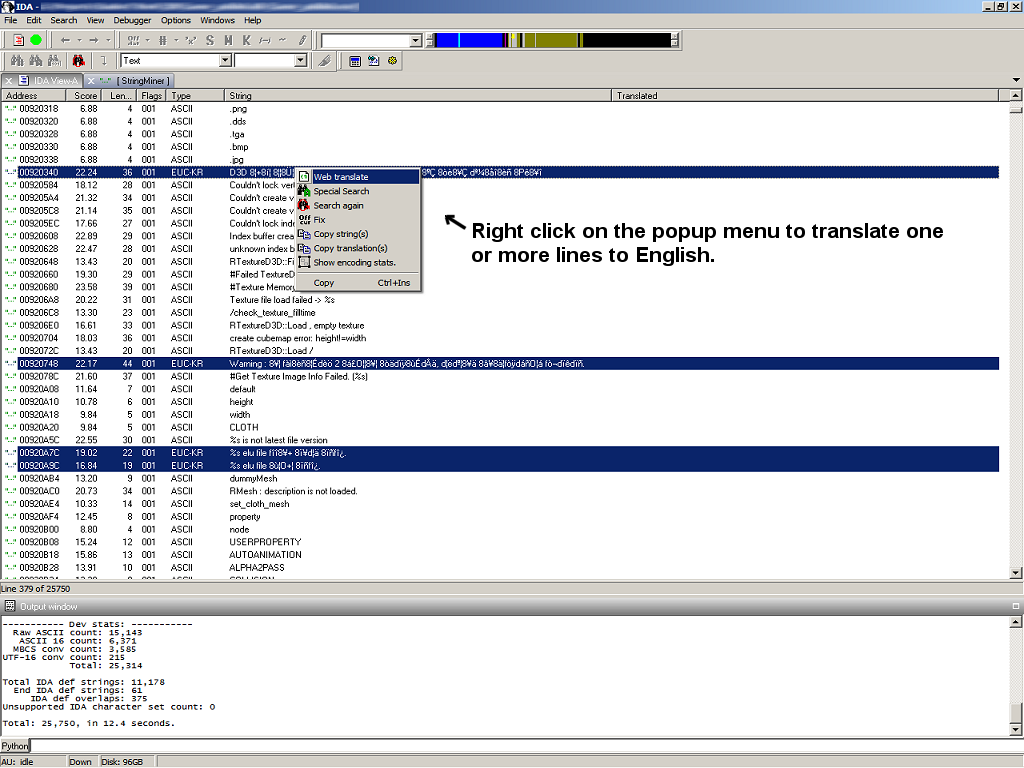
Uses the Microsoft Bing translator to translate to English:
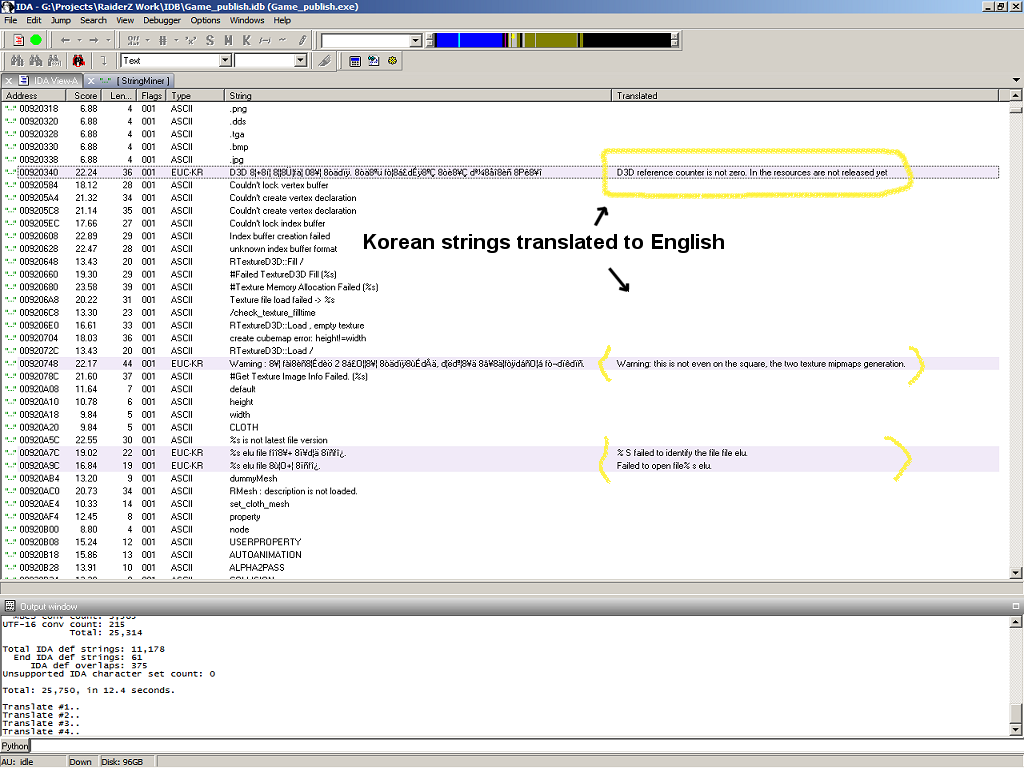
Now nicely translated!
12 thoughts on “IDA StringMiner™”
Leave a Reply
You must be logged in to post a comment.
And where can it be downloaded?
Thanks,
“Needs more work with practical things like a UI fancy enough to allow the selection of character sets of interest, etc., so don’t know when if at all if I release it all.”
I’m showing it off now to shamelessly self-promote my self, and in generally see if people are interested in it.
It is/was an unusually large project and It would take some polish before I’d feel comfortable releasing it
I have a Chinese OllyDbg plugin (dll) that contains (naturally) only Chinese Unicode text which I am dying to translate.
Can I beta test your plugin or shall I send you the dll for you to test how your plugin performs?
(Yours seems a million light years ahead in comparison to Luigi’s “Executable’s strings lister and replacer” )
Looking forward to this.
Nice plug-in! You should enter in the Hex-Rays plug-in contest =)
Oh yeah, and release it too!
I’d like to cast my vote here and say this is a really cool project. Thanks for sharing, Would love to see the finished project release and play with it myself.
A while back, you seemed to be working on a project called CFSearch. I wonder what happened with that? It showed great promise…
http://www.woodmann.com/forum/showthread.php?11306-Good-binary-code-profilers/page2
Thanks, yea I’ve been meaning to get back to branch/call tracing for a while now. In particular over the last few months when I came across articles about static call chain analysis in IDA et al.
The static way will never get the complete picture since: A) IDA has errors, B) you won’t see disconnected register based calls like ones for C++ vftables et al, that can be a substantial part of
a process.
My original idea was to make something for code as to what tools like Cheat Engine is for data.
To do differential operations on call hit counts to pinpoint functions of interest.
Like in a MORPG game RE to find something specific from exercising a particular feature.
The results at the time were kind of inconclusive at the time. But then again I didn’t completely rule out any error(s) in the process and didn’t do enough test cases.
What might be more useful is to record and, or, otherwise process call chains too.
The worst problem, although easy enough to solve, is that there is no native support for the basic BTS feature in Windows OSes (just the standard “trace” feature as part of the Debug API). It’s standard enough as most if not all popular Intel and AMD CPUs have support for it. It needs to be in the HAL and passed through the layers like the standard debug hardware features are. Anyhow “wish in one hand..”, the feature has to be added ideally via a driver as I did in the project.
It takes a DB of all the CPUs you want to support to have the right registers for it, etc.
I wonder what might be useful is some kind of open source project as a “Branch Trace Tool kit” supporting the various methods and most x86 CPUs, etc., where people could use it in various projects.
Perhaps somehow streaming/sharing the call data to user mode applications.
Hopefully I’ll some time to get back it this year..
yeah. Looks like ida pro just implemented support for this:
https://www.hex-rays.com/products/ida/support/tutorials/pin/pin_tutorial.pdf
Yea I’ve looked at that thing a bit but haven’t actually tried it yet.
It looks like it might be a good tool for somethings but I see some potential problems with it for a general technique.
For one, what it does is dissemble code and then do some kind of JIT like operation on it to facilitate it’s hooking, tracking, etc., features.
Hardly transparent, it alters the target code. Furthermore it’s totally dependent on knowing the code. Will it still disassemble so well if the code is obfuscated?
The CPU tracing mechanisms can be pretty transparent to the target process and doesn’t need these fancy and complex steps to work.
It’s been 2 years now! Why don’t you release it?